Cross Validation kurz und knapp:
Cross Validation ist eine statistische Methode, um die Leistung von Machine Learning-Modellen zu bewerten. Man teilt den Datensatz in mehrere Teile auf: Ein Teil wird zum Trainieren des Modells verwendet, während die anderen Teile zur Validierung dienen. Damit kann die Vorhersagefähigkeit des Modells überprüft werden.
Was ist Cross Validation?
Cross Validation (Kreuzvalidierung) ist ein Verfahren, um zu prüfen, wie gut die Vorhersagekraft eines statistischen Modells ist. Dabei wird der erwartete Vorhersage-Fehler geschätzt und untereinander verglichen.
Dabei teilen wir unsere Daten in Trainings- und Testdaten auf. Die Trainingsdaten bilden das Fundament unseres Algorithmus. Die Testdaten dienen dazu, zu überprüfen, wie viele Fehler der Algorithmus macht, um damit die Genauigkeit zu überprüfen.
Diese Genauigkeit kann man daraufhin mit unterschiedlichen Machine-Learning Algorithmen vergleichen, um das beste Modell zu finden. Alternativ können wir bei einer niedrigen Vorhersagegenauigkeit auch unsere Modellparameter anpassen oder unsere Daten aufbereiten.
Das Besondere bei diesen Methoden ist, dass keine weiteren Informationen neben den Trainingsdaten des Modells notwendig sind. Das ist häufig von großem Vorteil, wenn z. B. wenig Daten vorhanden sind und deswegen einen Großteil für das Training des Modells aufgewendet wird.
Dazu werden häufig drei Methoden verwendet: Holdout Methode, k-Fold Cross Validation und Leave-one-out.
Wie funktioniert Cross Validation?
k-Fold Cross Validation: Die Standard-Methode
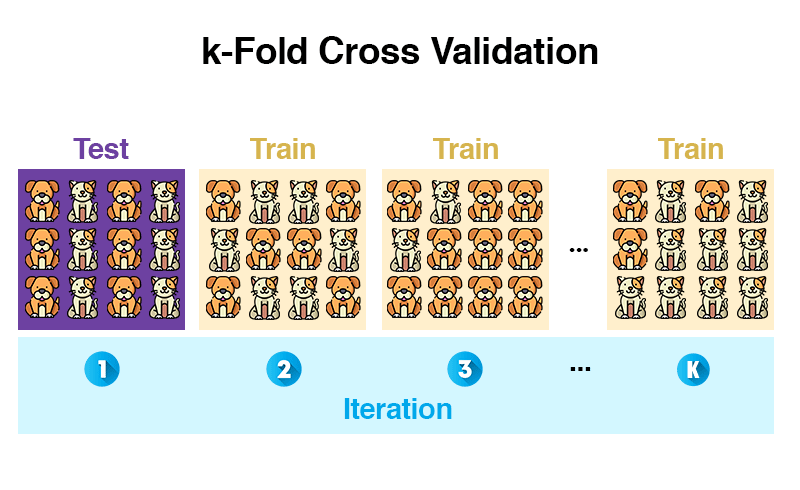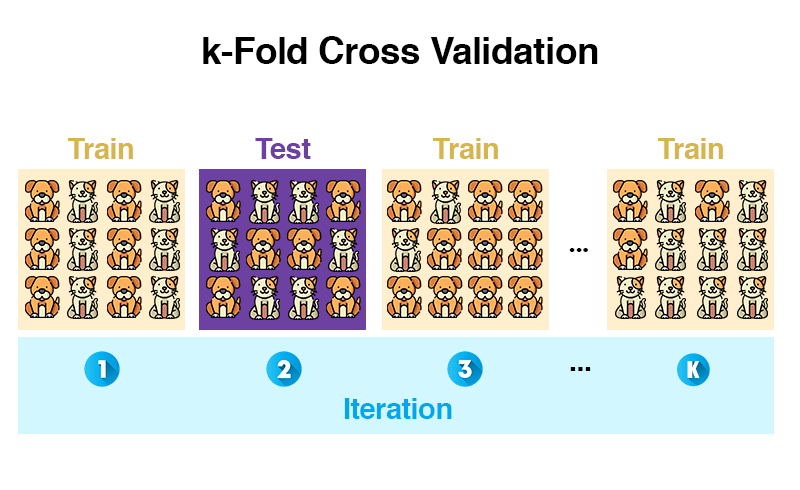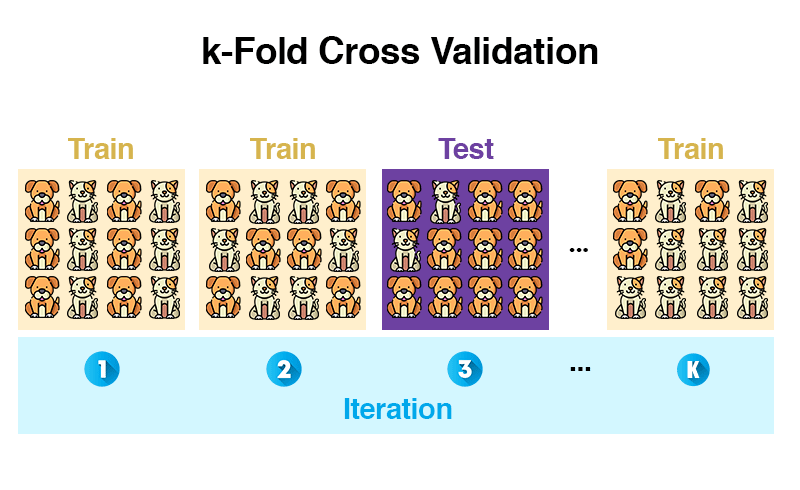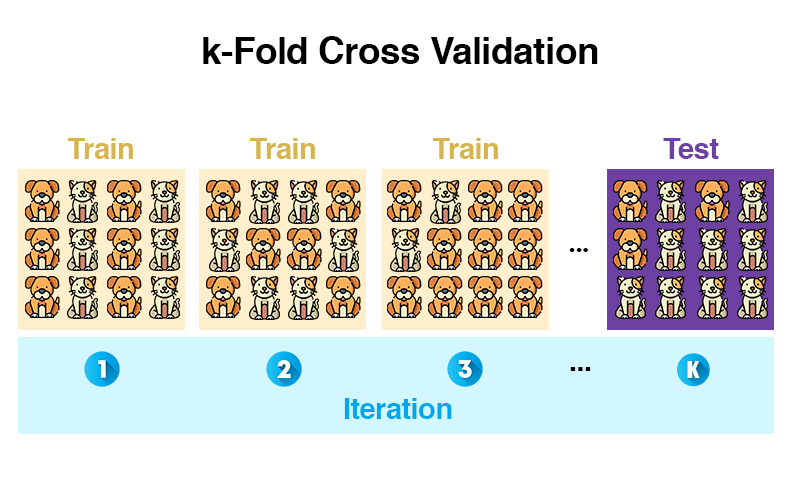
Die k-Fold Cross Validation teilt unsere Trainingsdaten in K zufällig gleich große Blöcke (= Folds) auf. Ein Fold an Daten wird zum Testen des Modells verwendet und die restlichen Folds zum Trainieren.
Bis hierhin ist es zur Holdout-Methode identisch. Der Unterschied ist, dass danach der ganze Prozess wiederholt wird. Mit dem Unterschied, dass ein anderer Fold zum Testen verwendet wird und alle anderen wieder zum Trainieren. Das ganze Prozedere wiederholt sich K mal, bis alle Folds zum Testen verwendet wurden.
Am Ende war jeder Block einmal für die Testdaten zuständig und daraus wird ein Durchschnitt berechnet. Damit reduzieren wir das Risiko, zufällig nicht-repräsentative Testdaten auszuwählen. Durch das Wiederholen wird das Ergebnis robuster, da die Varianz sinkt.
Holdout-Methode: Einfach Aufteilung großer Datensätze
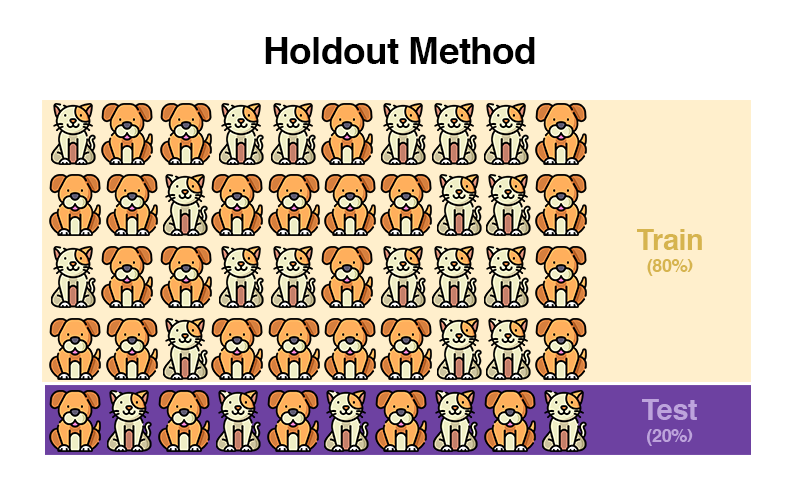
Bei einem größeren Datensatz werden die Daten in der Holdout-Methode bspw. 80/20 in Trainings- und Testdaten aufgeteilt. 80% der Daten werden als Trainingsdaten benutzt, 20% als Testdaten.
Die Trainingsdaten bilden das Fundament für das Modell und die Testdaten bewerten die Güte des Modells.
Ein wesentlicher Nachteil ist, dass man zufälligerweise ungünstige Trainings- und Testdaten erwischt, welche den Datensatz als „Lucky-Sample“ unrealistisch widerspiegeln. Im oberen Bild könnten die Trainingsdaten zufälligerweise nur aus Hunden bestehen. Die Katzen in den Testdaten könnten damit also nicht von unserem Modell erkannt werden, weil es im Training noch nie eine Katze gesehen hat.
Gegen dieses Problem verschafft die k-Fold Cross Validation Abhilfe.
Leave-One-Out: Anwendung bei kleinen Datensätzen
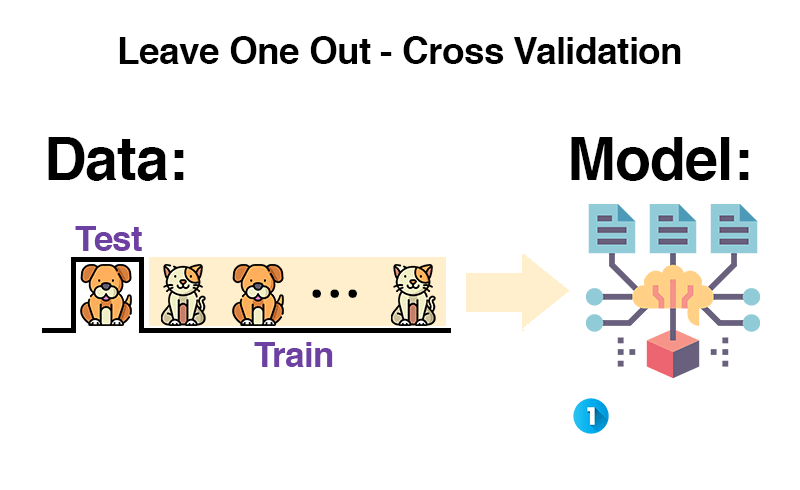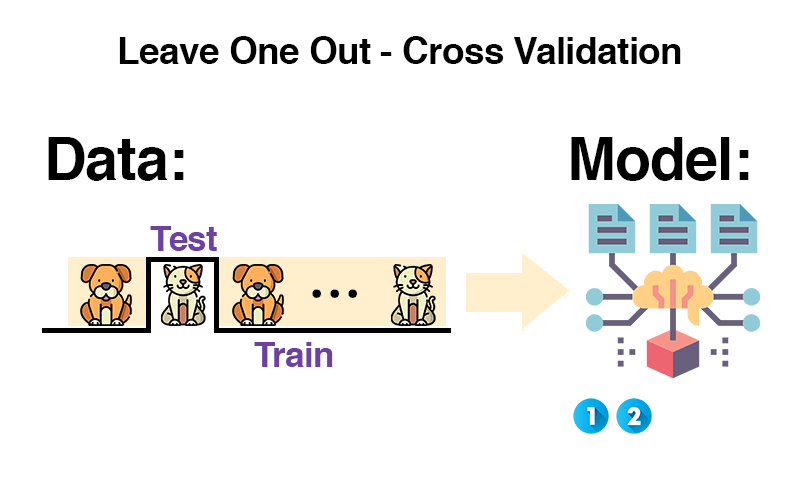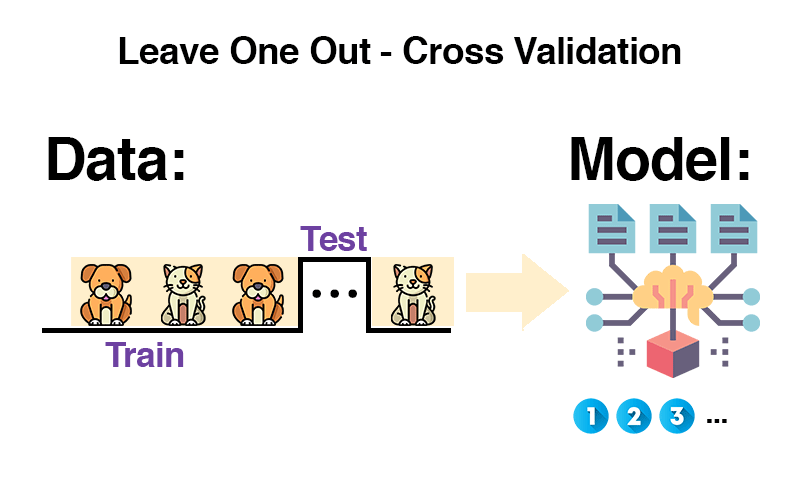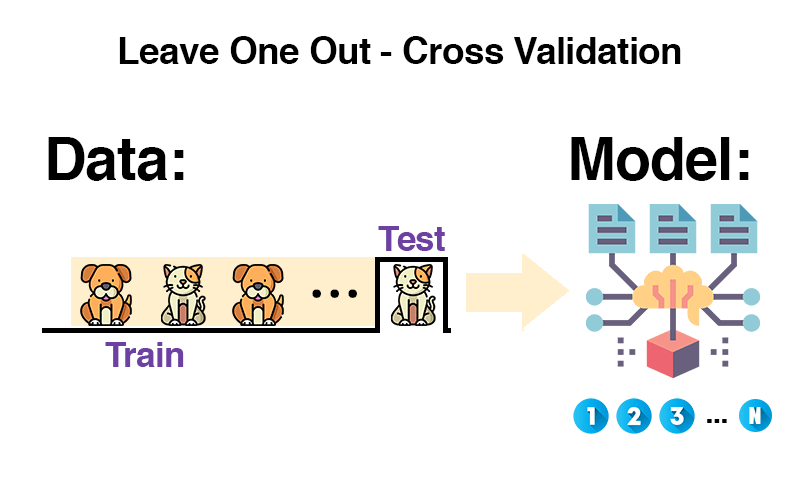
Die Leave-One-Out Methode wird meistens bei einer kleinen Anzahl von Daten genutzt. Daher möchte man so wenig Trainingsdaten wie möglich als Testdaten verlieren.
Man nimmt alle Daten, entfernt eine davon, trainiert mit den übrigen Daten und testet mit dem einen entfernten Beispiel. Dieses kommt zurück in die Trainingsdaten und das Prozedere wird mit einem neuen Element wiederholt. Das wird für alle Elemente im Datensatz durchgeführt und anschließend wird der Durchschnitt verwendet.
Diese Methode ist sehr rechenintensiv und eignet sich daher nicht bei großen Datensätzen. Trotzdem lohnt sich der Versuch bei genügend Rechenkapazität, da man die Daten hiermit ausgiebig testen kann.
Die Leave-One-Out Cross Validation ist quasi eine k-Fold Cross Validation, bei der die Anzahl der Folds (= k) der Anzahl aller Daten (= N) gleicht.
Cross-Validation in Python
Vorlage zum Kopieren
Hier findest du eine Vorlage zur Anwendung der k-Fold Cross Validation
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
# Bearbeite mich
csv_dataset = 'dein_datensatz.csv'
target_var_column = 'abhaengige_variable_spalte'
df = pd.read_csv(csv_dataset)
X = dataset.drop(target_var_column, axis=1)
y = dataset[target_var_column]
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kfold, scoring='r2')
print("Cross-Validation Scores: ", scores)
print("Average Score: ", scores.mean()) Schritt-für-Schritt Anleitung
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
import pandas as pd 1. Importiere die notwendigen Module
df = pd.read_csv('dein_datensatz.csv') 2. Lade die notwendigen Datensätze über Pandas in ein Dataframe.
target_var_column = 'abhaengige_variable_spalte'
X = dataset.drop(target_var_column, axis=1)
y = dataset[target_var_column] 3. Splitte die Daten in unabhängige- (X) und anhängige Variablen (y) auf. Benenne die Variable target_var_column in den Spaltennamen der abhängigen Variable um.
kfold = KFold(n_splits=5, shuffle=True, random_state=42) 4. Wähle die Anzahl der Folds im Parameter n_splits.
scores = cross_val_score(model, X, y, cv=kfold, scoring='r2')
print("Cross-Validation Scores: ", scores)
print("Average Score: ", scores.mean()) 5. Lass die Cross Validation laufen und gib die Ergebnisse aus
Zusammenfassung
Cross-Validation ist eine Methode, mit der man im Machine Learning die Daten in Trainings- und Testdaten aufteilt. Es hilft uns dabei einzuschätzen, wie die Genauigkeit des Modells ist. Dabei gibt es verschiedene Methodiken:
- k-Fold Cross Validation: Teilt die Daten in k gleich-große Gruppen auf. Eine Gruppe wird zum Testen genutzt und der Rest zum Trainieren.
- Holdout Cross Validation: Die Daten werden zufällig in zwei Gruppen aufgeteilt (bspw. 80:20) und zum Trainieren bzw. Testen benutzt
- Leave-One-Out Cross Validation: Jede Einheit im Datensatz wird einzeln zum Testen verwendet, während die restlichen Daten zum Trainieren genutzt werden.